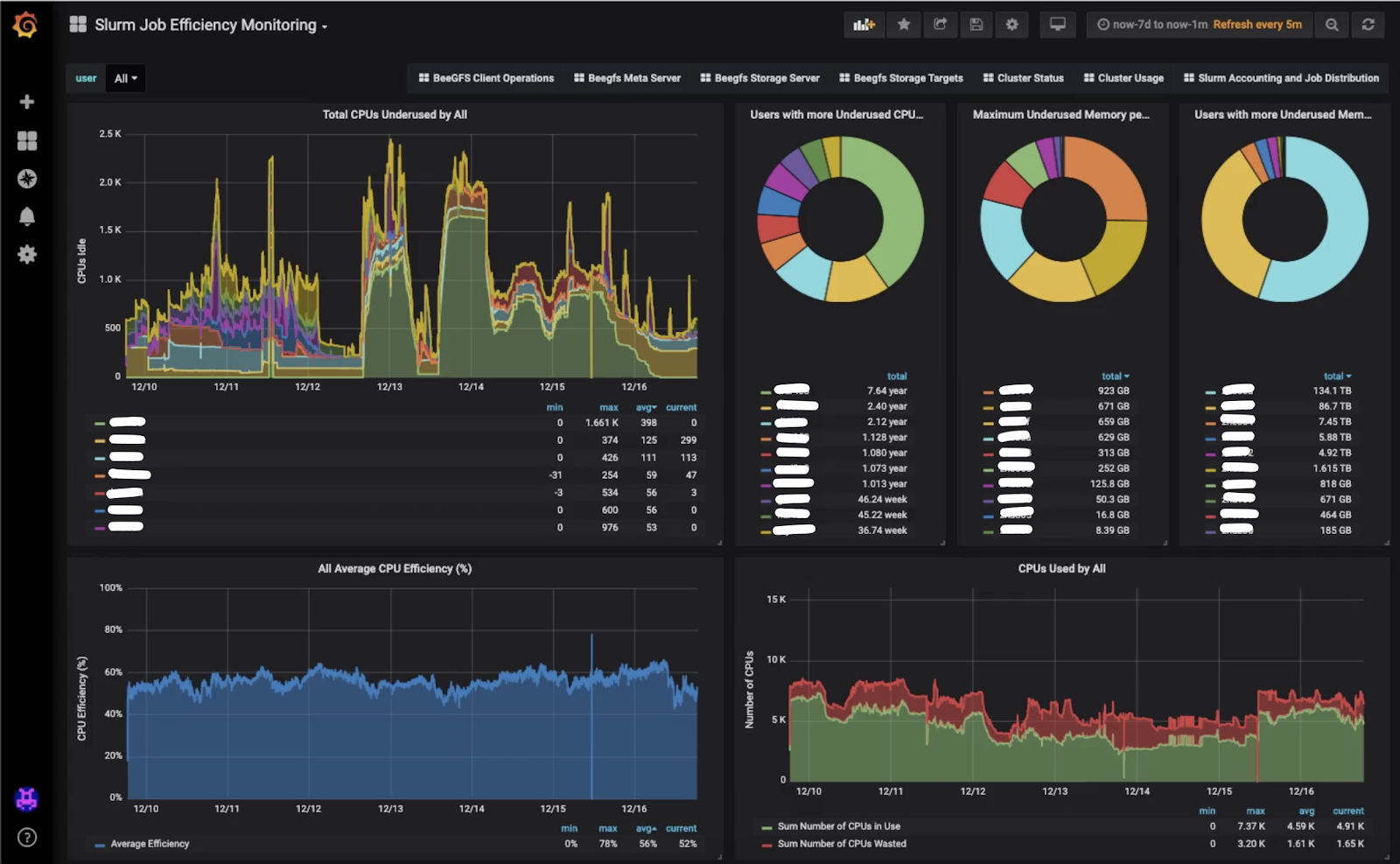
Barcelona, February 8th 2023 – Scientists and engineers at HPCNow! have developed a solution to monitor the status of HPC clusters in real time. The monitoring stack includes open-source solutions such as Grafana, Elasticsearch and Prometheus, for visualization and data storage, and Slurm plugins plus customized scripts to gather all the information needed by the system administrator. The solution is delivered using Docker Compose for single-node monitoring scenarios, or using Docker Swarm if high-availability is requested by the customer. Additionally, it includes the necessary dashboards to display the information gathered, some of them are:
The HPCNow! monitoring solution is flexible. It is provided taking into account the needs of the customer in terms of availability, variables to control and visualization.
This new technology is a must for those institutions that are facing cluster congestion issues, that want to maximize their return on investment, and/or to keep the cloud bursting budget under control. Additionally, it helps the HPC center to draw a line to define what is reasonable regarding resource usage and educate users on using the cluster properly if they are allocating more resources than needed.
Contact us at info@hpcnow.com if you have any questions!
More information:
– Improving efficiency in HPC clusters using monitoring tools
* Download the press release in pdf here
Parc Tecnològic
Marie Curie, 8 08042 Barcelona
+34 931640488
info@hpcnow.com
 See location
See location
61 Kahawairahi Drive
Beachlands
2018 - Auckland (New Zealand)
+64 (0) 22 344 2801
info@hpcnow.com
Contact us and we will help you.
